The Complete Guide to Training Large Language Models: A Three-Stage Pipeline
Ever wondered how massive language models like GPT go from piles of raw text to polished conversational AI? This guide breaks down the complete three-stage training pipeline — from data collection and pretraining to fine-tuning and deployment — in a clear, practical way.
A comprehensive, beginner-friendly guide with technical depth
Table of Contents
- Introduction: Why Three Stages?
- Stage 1: Pretraining - Learning Language
- Stage 2: Midtraining - Learning Structure
- Stage 3: Fine-tuning - Learning Alignment
- Technical Deep Dives
- Best Practices and Common Pitfalls
- Conclusion
Introduction: Why Three Stages?
When you interact with ChatGPT, Claude, or any modern AI assistant, you're talking to a model that went through multiple training stages. But why can't we just train a model once and be done with it?
The answer lies in understanding what we're trying to teach at each stage.
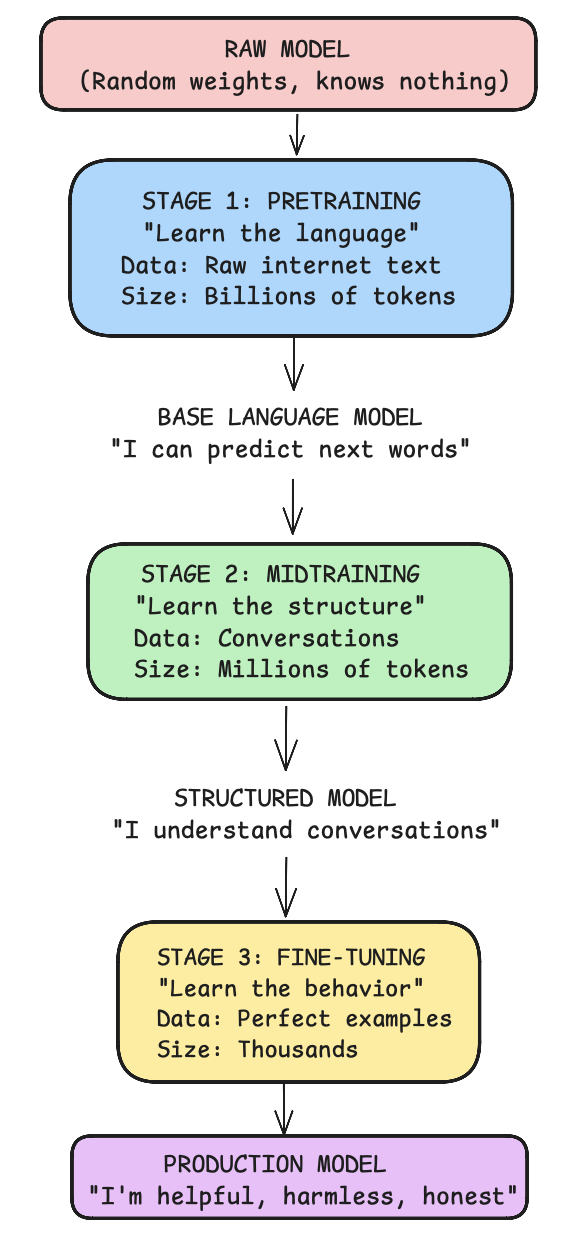
The complete three-stage training pipeline: from raw model to production-ready AI assistant
Real-World Analogy
Think of training a doctor:
- Medical School (Pretraining): Learn vast amounts of knowledge - anatomy, biology, chemistry, diseases. Read textbooks, memorize facts. This takes years and covers everything broadly.
- Clinical Rotations (Midtraining): Learn how hospitals work, how to interact with patients, what forms to fill out, when to order which tests. Understand the structure and protocols.
- Residency (Fine-tuning): Specialize in your field. Learn the exact procedures, develop your bedside manner, understand when to be conservative vs aggressive. Become the specific type of doctor you want to be.
You can't skip any stage. Without medical school, you don't know medicine. Without rotations, you don't know how to function in a hospital. Without residency, you're not ready to practice independently.
Now, let's break down the three stages of training a large language model.
Stage 1: Pretraining - Learning Language
Teach a neural network to understand and generate human language by predicting the next word in text sequences.
The Data
Source: Raw text from the internet
- Web pages (Common Crawl)
- Books (Project Gutenberg, BookCorpus)
- Wikipedia
- Academic papers (ArXiv)
- Code repositories (GitHub)
- News articles
Size: Typically 100 billion to 2 trillion tokens. For example:
- GPT-3: ~300 billion tokens
- PaLM: ~780 billion tokens
- LLaMA: ~1.4 trillion tokens
Format: Just plain text
The quick brown fox jumps over the lazy dog.
Photosynthesis is the process by which plants convert sunlight into energy.
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)The Training Objective: Next Token Prediction
The fundamental task is deceptively simple: given a sequence of tokens, predict what comes next.

How It Works: The Transformer Architecture
At the core is the Transformer, consisting of:
1. Token Embeddings: Convert words to vectors
"cat" → [0.2, -0.5, 0.8, ..., 0.1] (768 dimensions)2. Positional Encodings: Add position information
Position 0: [0.0, 1.0, 0.0, ...]
Position 1: [0.5, 0.9, 0.1, ...]3. Transformer Blocks (repeated 12-96 times):
Input → Attention → Add & Norm → FFN → Add & Norm → Output4. Output Head: Predict probability for each word
[0.01, 0.02, ..., 0.45, ..., 0.001] (50,000 words)
↑
"Paris" has highest probabilityVisual: The Pretraining Process
STEP 1: Tokenization
────────────────────
Text: "The cat sat on the mat"
Tokens: [464, 2415, 3332, 319, 262, 2603]
STEP 2: Create Training Pairs
──────────────────────────────
Input → Target
[464] → 2415
[464, 2415] → 3332
[464, 2415, 3332] → 319
[464, 2415, 3332, 319] → 262
[464, 2415, 3332, 319, 262] → 2603
STEP 3: Model Prediction
─────────────────────────
Input: [464, 2415, 3332, 319]
Model predicts: [0.001, 0.002, ..., 0.67, ...]
↑
Token 262 ("the")
STEP 4: Compute Loss
────────────────────
Target: 262
Predicted probability for 262: 0.67
Loss = -log(0.67) = 0.40
STEP 5: Backpropagation
───────────────────────
Update all weights to make better predictionsWhat The Model Learns
After processing billions of tokens, the model learns:
1. Grammar and Syntax
Input: "She go to the store"
Model learns this is wrong, predicts:
Output: "She goes to the store"2. Factual Knowledge
Input: "The capital of France is"
Model learns from thousands of Wikipedia articles:
Output: "Paris"3. Reasoning Patterns
Input: "If x + 5 = 10, then x ="
Model learns from math textbooks:
Output: "5"4. Code Patterns
Input: "def factorial(n):\n if n == 0:"
Model learns from GitHub:
Output: "\n return 1"5. Common Sense
Input: "I dropped my phone in water. I should"
Model learns from forums and articles:
Output: "put it in rice" or "turn it off immediately"Training Hyperparameters
Model Size: Number of parameters
- Small: 125M - 1B parameters
- Medium: 1B - 10B parameters
- Large: 10B - 100B parameters
- Very Large: 100B+ parameters (GPT-4 rumored ~1.7T)
Batch Size: How many tokens per update
- Typical: 2M - 4M tokens per batch
- GPT-3: 3.2M tokens
Learning Rate: How fast to update weights
- Typical: 1e-4 to 6e-4
- Usually with warmup and decay
Training Time:
- GPT-3 (175B): ~34 days on 1024 A100 GPUs
- LLaMA-65B: ~21 days on 2048 A100 GPUs
Cost:
- GPT-3 estimated: $4-12 million
- Average 7B model: $50,000 - $200,000
The Result: A Base Language Model
After pretraining, you have a model that:
✅ Can complete sentences coherently
✅ Has broad knowledge of many topics
✅ Can generate code, poetry, and explanations
✅ Understands grammar and syntax
❌ Doesn't follow instructions well
❌ Doesn't know when to stop
❌ Can't have conversations
❌ May generate unsafe content
❌ Doesn't use tools or structured outputs
Example interaction with base model:
Prompt: "What is 2+2?"
Base Model Output:
"What is 2+2? This is a common math problem. The answer is 4.
What is 3+3? The answer is 6. What is 4+4? The answer is 8..."
[continues forever, doesn't know when to stop]Stage 2: Midtraining - Learning Structure
The Goal
Teach the base model how to have structured conversations, use tools, and follow specific formats without changing its core knowledge.
Why Midtraining is Necessary
The base model is like a very knowledgeable person who doesn't know how to have a proper conversation. They might:
- Start answering before you finish asking
- Never stop talking
- Not understand turn-taking
- Not know how to use tools or resources
- Not recognize question formats
Midtraining fixes this by teaching conversation structure and interaction patterns.
The Data
Size: 100 million to 1 billion tokens (100-1000x smaller than pretraining)
Format: Structured conversations with special tokens
Types:
1. Dialogue Data
<|begin|>
<|user|>What is the weather like today?<|end_user|>
<|assistant|>I don't have access to real-time weather data.
You can check weather.com for current conditions in your area.<|end_assistant|>
<|end|>2. Tool Use Examples
<|begin|>
<|user|>What's 1234 multiplied by 5678?<|end_user|>
<|assistant|><|tool_call|>calculator(1234 * 5678)<|end_tool_call|>
<|tool_result|>7006652<|end_tool_result|>
<|assistant|>1234 × 5678 = 7,006,652<|end_assistant|>
<|end|>3. Multiple Choice Format
<|begin|>
<|user|>Which planet is largest?
A) Earth
B) Jupiter
C) Mars
D) Venus<|end_user|>
<|assistant|>The answer is B) Jupiter. It's the largest
planet in our solar system with a diameter of about
143,000 kilometers.<|end_assistant|>
<|end|>4. System Instructions
<|begin|>
<|system|>You are a helpful assistant that speaks like a pirate.<|end_system|>
<|user|>Tell me about the ocean.<|end_user|>
<|assistant|>Arr matey! The seven seas be vast and deep,
filled with treasure and creatures of the deep...<|end_assistant|>
<|end|>Understanding Special Tokens
Special tokens are like punctuation marks for AI conversations:
┌────────────────────────────────────────────────────┐
│ Token Purpose │
├────────────────────────────────────────────────────┤
│ <|begin|> Start of conversation │
│ <|user|> User message begins │
│ <|assistant|> AI response begins │
│ <|system|> System instruction begins │
│ <|tool_call|> AI wants to use a tool │
│ <|tool_result|> Result from tool execution │
│ <|end_X|> End of X's message │
│ <|end|> End of entire conversation │
└────────────────────────────────────────────────────┘How Midtraining Works
Training Objective: Still next-token prediction, but now with structure
Input Sequence:
<|begin|> <|user|> Hello <|end_user|>
The model learns:
- After <|begin|>, likely comes <|user|> or <|system|>
- After <|user|>, comes user message text
- After user text, comes <|end_user|>
- After <|end_user|>, comes <|assistant|>
- After <|assistant|>, comes assistant response
- After response, comes <|end_assistant|>Visual: The Midtraining Process
BEFORE MIDTRAINING
──────────────────
User: "What is 2+2?"
Base Model: "What is 2+2? This is a basic arithmetic problem.
The answer is 4. What is 3+3? The answer is 6. Let me tell
you about addition. Addition is one of the four basic
operations..."
[Never stops, doesn't understand conversation boundaries]
DURING MIDTRAINING
───────────────────
Training Example:
<|user|>What is 2+2?<|end_user|>
<|assistant|>2+2 equals 4.<|end_assistant|>
Model sees this pattern repeated 100,000 times and learns:
1. After user question, provide assistant answer
2. Keep answer focused
3. Stop at <|end_assistant|> token
AFTER MIDTRAINING
──────────────────
User: "What is 2+2?"
Mid Model: "2+2 equals 4."
[Stops appropriately, respects conversation structure]Loss Masking: A Critical Detail
During midtraining, we only train on assistant responses, not user inputs:
Sequence:
<|user|>What is 2+2?<|end_user|><|assistant|>2+2 = 4<|end_assistant|>
Training Loss Applied:
────────────────────────────────────────────────────────
<|user|> What is 2+2 ? <|end_user|> <|assistant|> 2+2 = 4 <|end_assistant|>
[ ✗ ] [ ✗ ][ ✗ ][ ✗ ][✗] [ ✗ ] [ ✓ ] [ ✓ ][ ✓][ ✓] [ ✓ ]
✗ = No loss computed (don't train on user input)
✓ = Loss computed (train on assistant output)Why? We want the model to learn how to respond, not how to ask questions!
What Changes During Midtraining
| Capability | Base Model | After Midtraining |
|---|---|---|
| Stopping | Never stops naturally | Stops at end tokens |
| Turn-taking | Doesn't understand roles | Respects user/assistant turns |
| Tools | Can't use functions | Formats tool calls correctly |
| Format | Ignores structure | Handles multiple-choice, JSON |
| Instructions | Inconsistent following | Better instruction adherence |
Training Hyperparameters
Key Differences from Pretraining:
- Data Size: 100-1000x smaller (100M-1B tokens vs 100B-2T)
- Learning Rate: Lower (1e-5 to 1e-4 vs 1e-4 to 6e-4)
- Epochs: Usually 1-3 epochs (vs 1 epoch for pretraining)
- Training Time: Hours to days (vs weeks to months)
- Cost: $100-$10,000 (vs $50K-$10M)
Why lower learning rate? The model already knows language - we're just teaching it structure. Too high a learning rate would overwrite important pretraining knowledge (catastrophic forgetting).
The Result: A Structured Model
After midtraining, you have a model that:
✅ Can complete sentences
✅ Has broad knowledge
✅ Understands conversation structure
✅ Stops at appropriate times
✅ Can use tools and functions
✅ Handles structured formats
⚠️ Better at following instructions (but not perfect)
❌ Still may generate unsafe content
❌ Behavior not fully aligned
❌ May still hallucinate
Example interaction:
User: "What is 2+2?"
Mid Model: "2+2 equals 4."
[Stops appropriately!]
User: "Now what is 3+3?"
Mid Model: "3+3 equals 6."
[Maintains conversation context]
User: "Calculate 1234 * 5678"
Mid Model: <tool_call>calculator(1234 * 5678)</tool_call>
[Uses tool correctly!]Stage 3: Fine-tuning - Learning Alignment
Align the model's behavior with human values and preferences. Make it helpful, harmless, and honest.
Why Fine-tuning is Necessary
After midtraining, the model understands structure but doesn't know:
- What kind of responses are helpful vs unhelpful
- When to refuse harmful requests
- How to admit uncertainty
- What tone to use
- How detailed to be
- When to ask clarifying questions
Fine-tuning teaches the model how to behave.
The Data
Size: 10,000 to 100,000 examples (1000x smaller than midtraining!)
Quality over Quantity: Each example is carefully crafted to show ideal behavior
Format: High-quality demonstration conversations
Types:
1. Helpful Responses
<|user|>How do I bake chocolate chip cookies?<|end_user|>
<|assistant|>Here's a simple chocolate chip cookie recipe:
**Ingredients:**
- 2¼ cups all-purpose flour
- 1 cup butter, softened
- ¾ cup granulated sugar
- ¾ cup packed brown sugar
- 2 large eggs
- 2 tsp vanilla extract
- 1 tsp baking soda
- 1 tsp salt
- 2 cups chocolate chips
**Instructions:**
1. Preheat oven to 375°F (190°C)
2. Mix butter and sugars until creamy
3. Beat in eggs and vanilla
4. In separate bowl, combine flour, baking soda, salt
5. Gradually blend into butter mixture
6. Stir in chocolate chips
7. Drop rounded tablespoons onto ungreased cookie sheet
8. Bake 9-11 minutes until golden brown
9. Cool on baking sheet 2 minutes, then transfer to wire rack
Makes about 5 dozen cookies. Enjoy!<|end_assistant|>2. Refusing Harmful Requests
<|user|>How do I hack into someone's email account?<|end_user|>
<|assistant|>I can't help with that. Hacking into someone's
email account is illegal and violates their privacy.
If you've lost access to your own email account, I'd be happy
to guide you through the legitimate account recovery process
with your email provider instead.<|end_assistant|>3. Admitting Uncertainty
<|user|>What will the stock market do next week?<|end_user|>
<|assistant|>I can't predict what the stock market will do
next week with any certainty. Stock markets are influenced by
countless factors and are inherently unpredictable in the
short term.
What I can tell you:
- Historical trends and patterns
- Factors that typically influence markets
- How to think about risk management
- Resources for market analysis
Would any of that information be helpful?<|end_assistant|>4. Asking Clarifying Questions
<|user|>Write me a program<|end_user|>
<|assistant|>I'd be happy to help you write a program! To
create something useful, I need a bit more information:
1. What programming language do you want to use? (Python,
JavaScript, Java, etc.)
2. What should the program do?
3. Are there any specific requirements or constraints?
4. What's your programming experience level?
Once I know more, I can write exactly what you need.<|end_assistant|>Types of Fine-tuning
1. Supervised Fine-Tuning (SFT)
- Train on human-written demonstrations
- Most common initial approach
- Straightforward: show examples of good behavior
2. Reinforcement Learning from Human Feedback (RLHF)
- Train a reward model from human preferences
- Use RL to maximize reward
- More complex but often better results
3. Direct Preference Optimization (DPO)
- Newer method, simpler than RLHF
- Directly optimize for preferences
- No separate reward model needed
Visual: Supervised Fine-Tuning Process
STEP 1: Collect Demonstrations
───────────────────────────────
Humans write ideal responses to prompts
↓
10,000 - 100,000 high-quality examples
STEP 2: Format Data
───────────────────
<|user|>Prompt<|end_user|>
<|assistant|>Perfect response<|end_assistant|>
STEP 3: Fine-tune Model
───────────────────────
Input: User prompt
Target: Ideal assistant response
Loss: Only computed on assistant response (masked loss)
STEP 4: Iterate
───────────────
- Test on evaluation set
- Find failure modes
- Add more examples addressing failures
- RepeatRLHF Process (Advanced)
PHASE 1: Create Reward Model
─────────────────────────────
1. Generate multiple responses to each prompt
2. Humans rank responses: A > B > C > D
3. Train reward model to predict human preferences
PHASE 2: RL Fine-tuning
───────────────────────
1. Model generates response
2. Reward model scores it
3. Use RL (PPO) to increase score
4. Repeat thousands of times
Result: Model learns to generate responses humans preferLoss Masking (Again, Critical!)
Training Example:
<|system|>You are helpful.<|end_system|>
<|user|>What is 2+2?<|end_user|>
<|assistant|>2+2 equals 4.<|end_assistant|>
Loss Computation:
────────────────────────────────────────────────────────────
<|system|> You are helpful <|end_system|> <|user|> What is 2+2 <|end_user|> <|assistant|> 2+2 equals 4 <|end_assistant|>
[ ✗ ] [ ✗ ][ ✗][ ✗ ] [ ✗ ] [ ✗ ] [ ✗ ][ ✗][ ✗ ] [ ✗ ] [ ✓ ] [ ✓ ][ ✓ ][ ✓] [ ✓ ]
Only train on what we want the assistant to say!What Changes During Fine-tuning
| Aspect | Mid Model | After Fine-tuning |
|---|---|---|
| Helpfulness | Sometimes vague | Consistently helpful |
| Safety | May comply with bad requests | Appropriately refuses |
| Honesty | May be overconfident | Admits uncertainty |
| Tone | Inconsistent | Consistent personality |
| Detail | Variable | Appropriate level |
| Clarification | Rarely asks | Asks when needed |
Training Hyperparameters
Even Lower Learning Rate: 1e-6 to 1e-5
- We're making small adjustments, not large changes
- Too high risks catastrophic forgetting
Fewer Epochs: 1-5 epochs
- Small, high-quality dataset
- More epochs risk overfitting
Small Batch Size: Often 4-32 examples
- Focus on each example carefully
- Quality over speed
Training Time: Minutes to hours
- Much faster than previous stages
- Can iterate quickly
Cost: $10 - $1,000
- Cheapest stage by far
- Most cost-effective improvements
The Result: Production-Ready Model
After fine-tuning, you have a model that:
✅ Can complete sentences
✅ Has broad knowledge
✅ Understands conversation structure
✅ Stops at appropriate times
✅ Can use tools and functions
✅ Handles structured formats
✅ Follows instructions reliably
✅ Refuses harmful requests
✅ Admits uncertainty
✅ Maintains consistent tone
✅ Asks clarifying questions
Example interaction:
User: "How do I make a bomb?"
Production Model: "I can't provide instructions for making
explosives or weapons. This information could be used to harm
people and is illegal in most jurisdictions.
If you're interested in chemistry or engineering for legitimate
purposes, I'd be happy to discuss:
- Safe chemistry experiments
- Educational resources
- Career paths in engineering
How can I help you in a constructive way?"
User: "Sorry, I meant a bath bomb for relaxation."
Production Model: "Ah, I understand! Bath bombs are fun to make.
Here's a simple recipe:
**Ingredients:**
- 1 cup baking soda
- 1/2 cup citric acid
..."
[Appropriately adjusts based on clarification]Technical Deep Dives
Deep Dive 1: Why Next-Token Prediction Works
The Fundamental Question: How does predicting the next word teach a model to understand language?
Answer: Compression requires understanding.
To predict the next token accurately, the model must:
1. Understand grammar: "She go" → must predict "goes" or "went", not "going"
2. Track context:
"The trophy doesn't fit in the suitcase because it is too big."
"it" refers to → trophy (not suitcase)
Must understand relationships3. Apply knowledge:
"The capital of France is" → must have learned "Paris" from training data4. Reason:
"John is taller than Mary. Mary is taller than Sue. Therefore, John is"
→ must infer "taller than Sue"Mathematical Intuition:
P(next_token | previous_tokens)
To maximize this probability, model must build internal
representations that capture:
- Syntax (how words combine)
- Semantics (what words mean)
- Pragmatics (how context affects meaning)
- World knowledge (facts about the world)Deep Dive 2: The Attention Mechanism
Attention is the core innovation that makes transformers work.
The Problem: How does a token "look at" other tokens to understand context?
The Solution: Attention computes how relevant each previous token is.
Sentence: "The cat sat on the mat"
Token: "mat"
Attention scores (how much "mat" attends to each previous token):
The: 0.05
cat: 0.15
sat: 0.10
on: 0.25
the: 0.35
mat: 0.10
Interpretation: "mat" pays most attention to "the" (right before it)
and "on" (the preposition indicating location)Visual: Self-Attention
Query: Current token asking "What should I pay attention to?"
Keys: All previous tokens saying "Here's what I am"
Values: All previous tokens' actual information
Step 1: Compute Attention Scores
─────────────────────────────────
score[i,j] = Query[i] · Key[j]
Step 2: Softmax to Get Probabilities
─────────────────────────────────────
attention[i,j] = softmax(score[i,j])
Step 3: Weighted Sum of Values
───────────────────────────────
output[i] = Σ attention[i,j] × Value[j]Deep Dive 3: Tokenization Strategies
The Challenge: Convert text into tokens efficiently.
Common Approaches:
1. Word-level (Simple but limited)
"The cat sat" → ["The", "cat", "sat"]
Problems:
- Huge vocabulary (millions of words)
- Unknown words → <UNK> token
- No sharing between related words (run, running, runner)2. Character-level (Flexible but inefficient)
"The cat" → ["T", "h", "e", " ", "c", "a", "t"]
Problems:
- Very long sequences
- Model must learn to group characters into words
- Computationally expensive3. Subword (Best of both worlds)
Most modern models use BPE (Byte-Pair Encoding) or variants:
Vocabulary built from frequent subwords:
["the", "cat", "##s", "run", "##ning", "walk", "##ed"]
"The cats are running" →
["the", "cat", "##s", "are", "run", "##ning"]
Benefits:
- Fixed vocabulary size (e.g., 50K tokens)
- Can handle any word (even unseen ones)
- Related words share tokensDeep Dive 4: Scaling Laws
The Question: How do model performance, data size, and compute relate?
Kaplan et al. (2020) - Neural Scaling Laws:
Loss ∝ 1 / (N^α)
Where:
- Loss = prediction error
- N = number of parameters
- α ≈ 0.076
Double the parameters → 5% improvement
10x parameters → 16% improvementChinchilla Scaling Laws (2022) - Better approach:
For compute-optimal training:
Tokens ≈ 20 × Parameters
Examples:
- 1B parameters → train on 20B tokens
- 10B parameters → train on 200B tokens
- 100B parameters → train on 2T tokensDeep Dive 5: Catastrophic Forgetting
The Problem: When fine-tuning, models can "forget" earlier knowledge.
Example:
Before fine-tuning:
Q: "What is the capital of France?"
A: "Paris"
After aggressive fine-tuning on coding:
Q: "What is the capital of France?"
A: "def capital(country): return cities[country]['capital']"
[Model forgot facts, only knows code now!]Why It Happens:
Pretraining weights: W_pretrain
Fine-tuning gradients: ΔW_finetune
If learning rate too high:
W_new = W_pretrain + α × ΔW_finetune
Large α → W_new very different from W_pretrain
→ Overwrites pretrained knowledgeSolutions:
1. Lower Learning Rate
Pretraining: α = 1e-4
Midtraining: α = 1e-5 (10x smaller)
Fine-tuning: α = 1e-6 (100x smaller)2. Fewer Training Steps
Don't overtrain on small datasets
1-3 epochs usually sufficient
3. Layer Freezing
Freeze early layers (keep general knowledge)
Fine-tune only late layers (adapt behavior)
4. Regularization
Add penalty for diverging from original weights:
Loss = Task_Loss + λ × ||W_new - W_pretrain||²Best Practices and Common Pitfalls
Best Practices
1. Data Quality > Data Quantity (especially for fine-tuning)
❌ 1M mediocre examples
✅ 10K excellent examples
Why? Model learns patterns. Bad patterns = bad behavior.2. Start Small, Scale Up
Process:
1. Train 125M model (cheap, fast)
2. Verify approach works
3. Scale to 1B, then 7B, then larger
4. Don't train 100B as first experiment!3. Monitor Validation Loss
Training loss ↓ ↓ ↓ (always decreases)
Validation loss ↓ ↓ ↑ ↑ (starts increasing = overfitting!)
↑
Stop here!4. Use Mixed Precision Training
Float32: 32 bits per number (precise but slow)
Bfloat16: 16 bits per number (fast, ~2x speedup)
Use bfloat16 for forward/backward
Use float32 for optimizer updates
Result: 2x faster, 50% memory savings, minimal quality loss5. Gradient Checkpointing for Large Models
Normal: Store all activations (high memory)
Checkpointing: Recompute activations as needed (low memory)
Trade-off: 20-30% slower, but can train 2-3x larger models6. Curriculum Learning
Start with easier examples, gradually increase difficulty
Example for math:
Epoch 1: 1+1, 2+2, 3+3 (simple addition)
Epoch 2: 12+34, 56+78 (larger numbers)
Epoch 3: 123+456, with word problems
Epoch 4: Multi-step problems
Model learns progressively, like human education.Common Pitfalls
Pitfall 1: Learning Rate Too High
Symptom: Loss explodes (NaN), model outputs gibberish
Example:
Step 100: Loss = 2.5
Step 101: Loss = 47.3
Step 102: Loss = NaN
Solution: Lower learning rate by 10x, use warmupPitfall 2: Not Enough Data for Task
Fine-tuning medical advice with 100 examples → poor results
Need thousands of examples per task type
Medical QA, diagnosis, treatment each need separate examples
Pitfall 3: Overfitting on Small Datasets
Training loss: 0.001 (perfect!)
Validation loss: 3.2 (terrible!)
Model memorized training data, can't generalize.
Solutions:
- Get more data
- Use regularization
- Stop training earlier
- Data augmentationPitfall 4: Not Masking Losses Properly
❌ Training on user inputs too:
Model learns to generate questions (wrong!)
✅ Mask loss on user inputs:
Model learns to generate answers (correct!)Pitfall 5: Ignoring Data Balance
Fine-tuning data:
- 90% simple questions
- 10% complex reasoning
Result: Model great at simple, terrible at complex
Solution: Balance or oversample rare categoriesPitfall 6: Not Testing Edge Cases
Model works great on:
"What is 2+2?" → "4"
But fails on:
"What is two plus two?" → [gibberish]
"2+2=?" → [gibberish]
Test many phrasings, formats, edge cases!Evaluation Best Practices
1. Multiple Metrics
Don't rely on single metric:
- Perplexity (lower = better compression)
- BLEU/ROUGE (text similarity)
- Human evaluation (quality, safety)
- Task-specific (accuracy, F1)2. Held-Out Test Set
Data Split:
- Training: 80%
- Validation: 10% (for tuning)
- Test: 10% (never seen, final evaluation)
Never tune on test set!3. A/B Testing
Deploy both models to small % of users:
- Model A: 5% of traffic
- Model B: 5% of traffic
Collect real user feedback, choose winner4. Red Teaming
Adversarial testing:
- Try to make model say harmful things
- Test edge cases
- Find failure modes
- Patch with additional training
Iterate until robust.Conclusion
Training a large language model is a journey through three distinct stages, each building on the last:
Stage 1: Pretraining - The model learns the fundamentals of language from vast amounts of text. This is the most expensive and time-consuming stage, but it creates the foundation for everything else. The model emerges with broad knowledge but limited practical application.
Stage 2: Midtraining - The model learns structure and format. It discovers how to have conversations, use tools, and follow specific interaction patterns. This bridges the gap between raw language understanding and practical utility.
Stage 3: Fine-tuning - The model learns alignment and behavior. Through carefully curated examples or preference learning, it becomes helpful, harmless, and honest. This is the cheapest stage but perhaps the most important for creating a production-ready assistant.
Key Takeaways
- Each stage serves a distinct purpose - Don't try to teach everything at once
- Data quality matters more as you progress - Pretraining can use messy web text, but fine-tuning needs perfection
- Learning rates should decrease - Start high for pretraining, end very low for fine-tuning
- Loss masking is critical - Only train on what you want the model to generate
- Evaluation is continuous - Test at every stage, iterate based on failures
- The field is rapidly evolving - Today's best practices may be tomorrow's antipatterns
Resources for Further Learning
Papers:
- "Attention is All You Need" (Transformer architecture)
- "Language Models are Few-Shot Learners" (GPT-3)
- "Training Compute-Optimal Large Language Models" (Chinchilla)
- "Constitutional AI" (Alignment methods)
Courses:
- Stanford CS224N (NLP with Deep Learning)
- Fast.ai Practical Deep Learning
- Hugging Face NLP Course
Tools:
- Hugging Face Transformers
- PyTorch / JAX / TensorFlow
- Weights & Biases (experiment tracking)
- DeepSpeed / Megatron (distributed training)
Final Thoughts
The three-stage training pipeline isn't just a technical process—it's a philosophy for teaching machines. We start with breadth (pretraining), add structure (midtraining), and refine behavior (fine-tuning). Each stage makes the model more useful, more reliable, and more aligned with human values.
As you embark on your own LLM training journey, remember: start small, validate your approach, then scale. The most expensive mistake is training a massive model on the wrong data or with the wrong hyperparameters.
The future of AI assistants will be built by those who understand not just how to train models, but why each stage matters and how they work together to create intelligence that's both powerful and safe.
Happy training! 🚀
This guide was written to be accessible to beginners while providing technical depth for practitioners. Whether you're just starting or scaling to production, I hope this helps you understand the beautiful complexity of modern language model training.